
The search for models that can efficiently process multidimensional data, ranging from images to complex time series, has become increasingly crucial. Earlier Transformer models, renowned for their ability to handle various tasks, often struggle with long sequences due to their quadratic computational complexity. This limitation has sparked a surge of interest in developing architectures that scale better and enhance performance when dealing with large-scale datasets.
The efficiency of handling long data sequences is pivotal, especially as the amount and complexity of data in applications such as image processing and time series forecasting continue to grow. The computational demands of existing methods pose significant challenges, pushing researchers to innovate architectures that streamline processing without sacrificing accuracy. Selective State Space Models (S6) have emerged as a promising solution, selectively focusing computational resources on the most informative data segments, potentially revolutionizing the efficiency and effectiveness of data processing.
Researchers from Cornell University and the NYU Grossman School of Medicine present MambaMixer, a novel architecture featuring data-dependent weights. This architecture leverages a unique dual selection mechanism, the Selective Token and Channel Mixer, to efficiently navigate tokens and channels. A weighted averaging process further augments this dual selection mechanism to ensure seamless information flow across the model’s layers for optimizing processing efficiency and model performance.
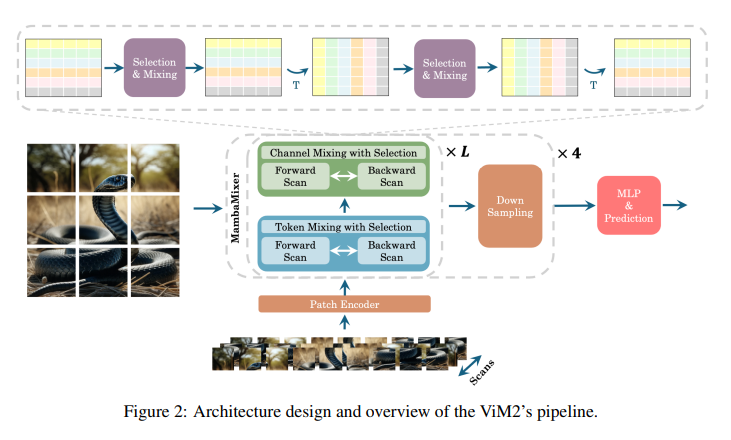
The utility and effectiveness of the MambaMixer architecture are exemplified in its specialized applications: the Vision MambaMixer (ViM2) for image-related tasks and the Time Series MambaMixer (TSM2) for forecasting time series data. These implementations highlight the architecture’s versatility and power. For instance, in challenging benchmarks like ImageNet, ViM2 achieves competitive performance against well-established models. Still, it surpasses SSM-based vision models, demonstrating superior efficiency and accuracy in image classification, object detection, and semantic segmentation tasks.
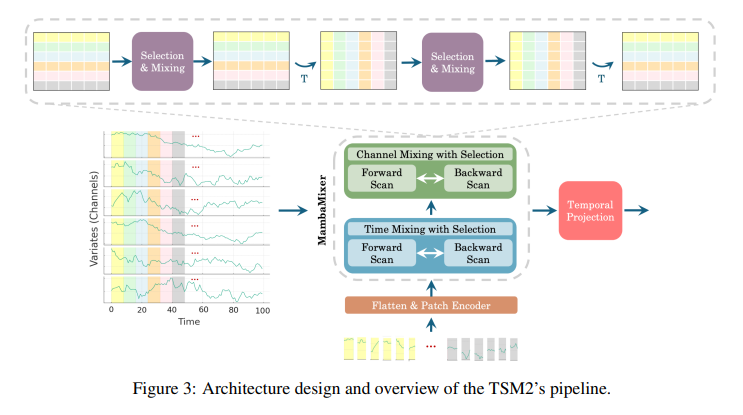
ViM2 has demonstrated competitive performance in challenging benchmarks like ImageNet. It achieved top-1 classification accuracies of 82.7%, 83.7%, and 83.9% for its Tiny, Small, and Base variants, respectively, outperforming well-established models like ViT, MLP-Mixer, and ConvMixer in certain configurations. A weighted averaging mechanism enhances the information flow and captures the complex dynamics of features, contributing to its state-of-the-art performance. TSM2 showcases groundbreaking results in time series forecasting, setting new records in various benchmarks. For instance, its application to the M5 dataset demonstrates an improvement in WRMSSE scores.

In conclusion, as datasets continue to expand in size and complexity, the development of models like MambaMixer, which can efficiently and selectively process information, becomes increasingly essential. This architecture represents a critical step forward, offering a scalable and effective framework for tackling the challenges of modern machine-learning tasks. Its success in both vision and time series modeling tasks demonstrates its potential and inspires further research and development in efficient data processing methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter.
Don’t Forget to join our 39k+ ML SubReddit
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.




















