
In the rapidly advancing domain of artificial intelligence, the efficient operation of large language models (LLMs) on consumer-level hardware represents a significant technical challenge. This issue arises from the inherent trade-off between the models’ size and computational efficiency. Compression methods, including direct and multi-codebook quantization (MCQ), have offered partial solutions to minimize these AI behemoths’ memory requirements. However, these approaches often compromise model performance, leaving a gap for innovation in extreme model compression techniques.
A pioneering strategy called Additive Quantization for Language Models (AQLM) by researchers from HSE University, Yandex Research, Skoltech, IST Austria, and NeuralMagic focused on minimizing this trade-off target by reducing the bit count per model parameter to an astonishingly low range of 2 to 3 bits. This strategy adopts and refines additive quantization, a technique previously confined to information retrieval for the specific challenges of LLM compression.
AQLM distinguishes itself by preserving and, in some instances, enhancing the accuracy of compressed models, particularly in scenarios demanding extreme compression. This is achieved through a novel two-pronged approach that includes the learned additive quantization of weight matrices in a manner that adapts to input variability and a sophisticated joint optimization of codebook parameters across layer blocks. This dual strategy propels AQLM to the forefront of LLM compression technologies, setting new standards in the field.
One of the standout features of AQLM is its practical applicability across various hardware platforms. The researchers behind AQLM have provided implementations demonstrating the method’s effectiveness on GPU and CPU architectures, ensuring its utility in real-world applications. This practicality is underpinned by a detailed evaluation of contemporary compression techniques, where AQLM consistently surpasses its competitors. It shines especially in extreme compression settings, demonstrating a remarkable ability to minimize model size without degrading performance. This is evidenced by AQLM’s superior performance in metrics such as model perplexity and accuracy in zero-shot tasks, highlighting its efficiency in maintaining the integrity of the compressed model.
The comparative analysis of AQLM against other leading compression methodologies reveals its unique position in the landscape of LLM compression. Unlike other approaches that often require a compromise between model size and accuracy, AQLM maintains or improves performance across a spectrum of metrics. This advantage is particularly evident in extreme compression, where AQLM sets new benchmarks in efficiency and effectiveness. The method’s success in this domain is a testament to the innovative approach taken by the researchers, combining learned additive quantization with joint optimization techniques to achieve unparalleled results.
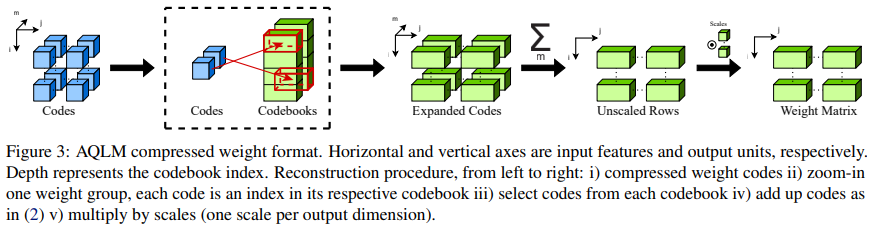
In conclusion, AQLM emerges as a groundbreaking approach in the quest for efficient compression of LLMs. By addressing the critical challenge of reducing the model size without sacrificing accuracy, AQLM paves the way for deploying advanced AI capabilities on a broader array of devices. Its innovative use of additive quantization tailored to LLMs and the method’s practical implementations on various hardware platforms mark a significant advancement in making AI more accessible. The impressive performance of AQLM, validated through rigorous evaluations, positions it as a beacon of innovation in LLM compression.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponent of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcement Learning”.






![30 Best Python Projects Beginner to Pro With Code [2024]](https://news.pourover.ai/wp-content/themes/jnews/assets/img/jeg-empty.png)













