
As language models become increasingly advanced, concerns have arisen around the ethical and legal implications of training them on vast and diverse datasets. If the training data is not properly understood, it could leak sensitive information between the training and test datasets. This could expose personally identifiable information (PII), introduce unintended biases or behaviors, and ultimately produce lower-quality models than expected. The lack of comprehensive information and documentation surrounding these models creates significant ethical and legal risks that must be addressed.
A team of researchers from various institutions, including MIT, Harvard Law School, UC Irvine, MIT Center for Constructive Communication, Inria, Univ. Lille Center, Contextual AI, ML Commons, Olin College, Carnegie Mellon University, Tidelift, and Cohere For AI have demonstrated their commitment to promoting transparency and responsible utilization of datasets by releasing a comprehensive audit. The audit includes Data Provenance Explorer, an interactive user interface that enables practitioners to trace and filter data provenance for widely used open-source fine-tuning data collections.
Copyright laws provide authors exclusive ownership of their work, while open-source licenses encourage collaboration in software development. However, supervised AI training data presents unique challenges for open-source licenses in managing data effectively. The interaction between copyright and permits within collected datasets is yet to be determined, with legal challenges and uncertainties surrounding the application of relevant laws to generative AI and supervised datasets. Previous work has stressed the importance of data documentation and attribution, with Datasheets and other studies highlighting the need for comprehensive documentation and curation rationale for datasets.
The study conducted by researchers involved manual retrieval of pages and automatic extraction of licenses from HuggingFace configurations and GitHub pages. They also utilized the Semantic Scholar public API to retrieve academic publication release dates and citation counts. To ensure fair treatment across languages, the researchers used a series of data properties in characters, such as text metrics, dialog turns, and sequence length. In addition, they conducted a landscape analysis to trace the lineage of over 1800 text datasets, examining their source, creators, license conditions, properties, and subsequent use. To facilitate the audit and tracing processes, they developed tools and standards to improve dataset transparency and responsible use.
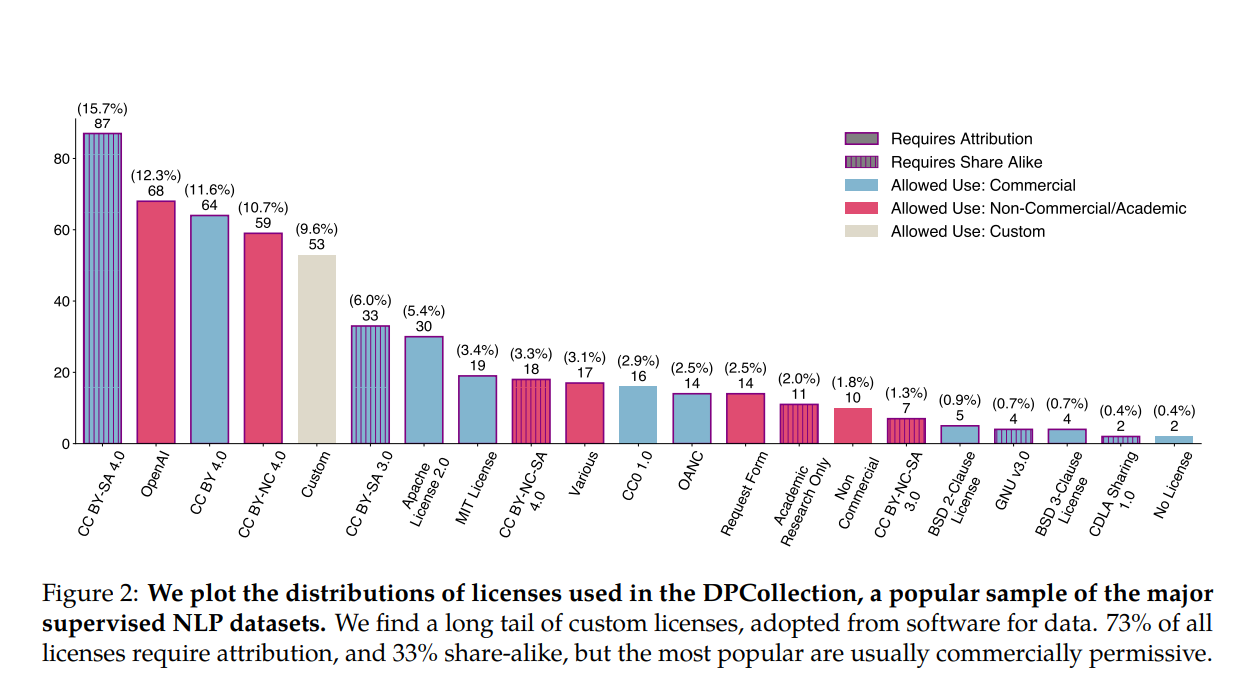
The landscape analysis has revealed stark differences in the composition and focus of commercially available open and closed datasets. The datasets that are difficult to access dominate essential categories such as lower resource languages, more creative tasks, wider topic variety, and newer and more synthetic training data. The study has also highlighted the problem of misattribution and the incorrect use of frequently used datasets. On popular dataset hosting sites, licenses are frequently miscategorized, and license omission rates exceed 70%, with error rates of over 50%. The study emphasizes the need for comprehensive data documentation and attribution. It also highlights the challenges of synthesizing documentation for models trained on multiple data sources.
The study concludes that there are significant differences in the composition and focus of commercially open and closed datasets. Impenetrable datasets monopolize important categories, indicating a deepening divide in the data types available under different license conditions. The study found frequent miscategorization of licenses on dataset hosting sites and high rates of license omission. This points to trouble in misattribution and informed use of popular datasets, raising concerns about data transparency and responsible use. The researchers released their entire audit, including the Data Provenance Explorer, to contribute to ongoing improvements in dataset transparency and reliable use. The landscape analysis and tools developed in the study aim to improve dataset transparency and understanding, addressing the legal and ethical risks associated with training language models on inconsistently documented datasets.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..









- Trending
- Comments
- Latest










