
Image by Author
Running LLMs (Large Language Models) locally has become popular as it provides security, privacy, and more control over model outputs. In this mini tutorial, we learn the easiest way of downloading and using the Llama 3 model.
Llama 3 is Meta AI’s latest family of LLMs. It is open-source, comes with advanced AI capabilities, and improves response generation compared to Gemma, Gemini, and Claud 3.
What is Ollama?
Ollama/ollama is an open-source tool for using LLMs like Llama 3 on your local machine. With new research and development, these large language models do not require large VRam, computing, or storage. Instead, they are optimized for use in laptops.
There are multiple tools and frameworks available for you to use LLMs locally, but Ollama is the easiest to set up and use. It lets you use LLMs directly from a terminal or Powershell. It is fast and comes with core features that will make you start using it immediately.
The best part of Ollama is that it integrates with all kinds of software, extensions, and applications. For example, you can use the CodeGPT extension in VScode and connect Ollama to start using Llama 3 as your AI code assistant.
Installing Ollama
Download and Install Ollama by going to the GitHub repository Ollama/ollama, scrolling down, and clicking the download link for your operating system.
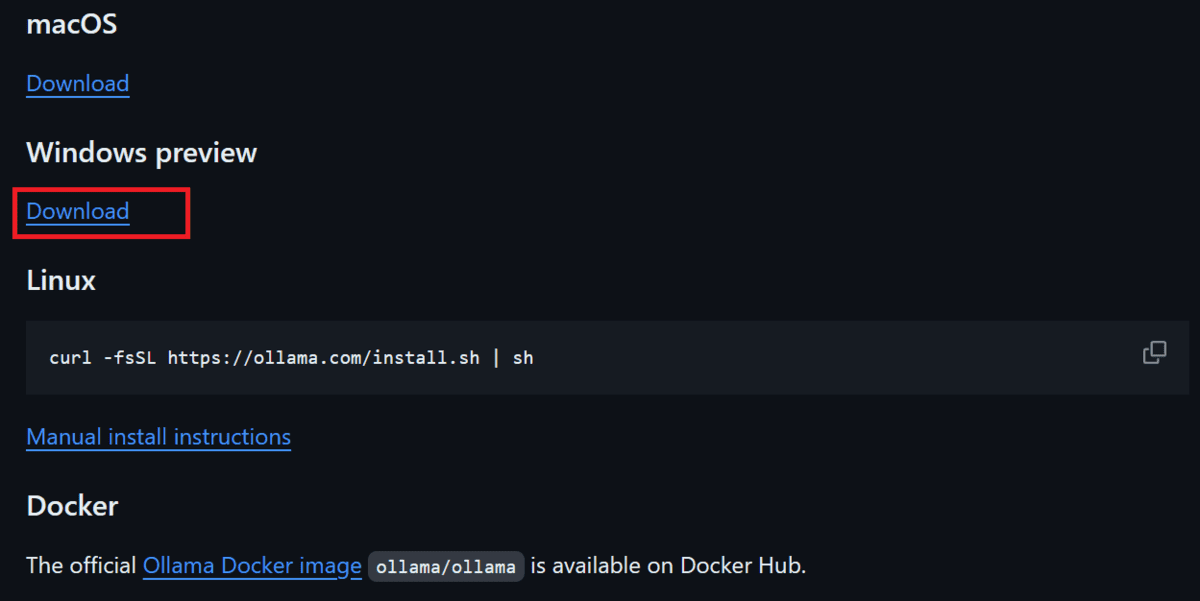 Image from ollama/ollama | Download option for various operating systems
Image from ollama/ollama | Download option for various operating systems
After Ollama is successfully installed it will show in the system tray as shown below.

Downloading and Using Llama 3
To download the Llama 3 model and start using it, you have to type the following command in your terminal/shell.
Depending on your internet speed, it will take almost 30 minutes to download the 4.7GB model.
Apart from the Llama 3 model, you can also install other LLMs by typing the commands below.
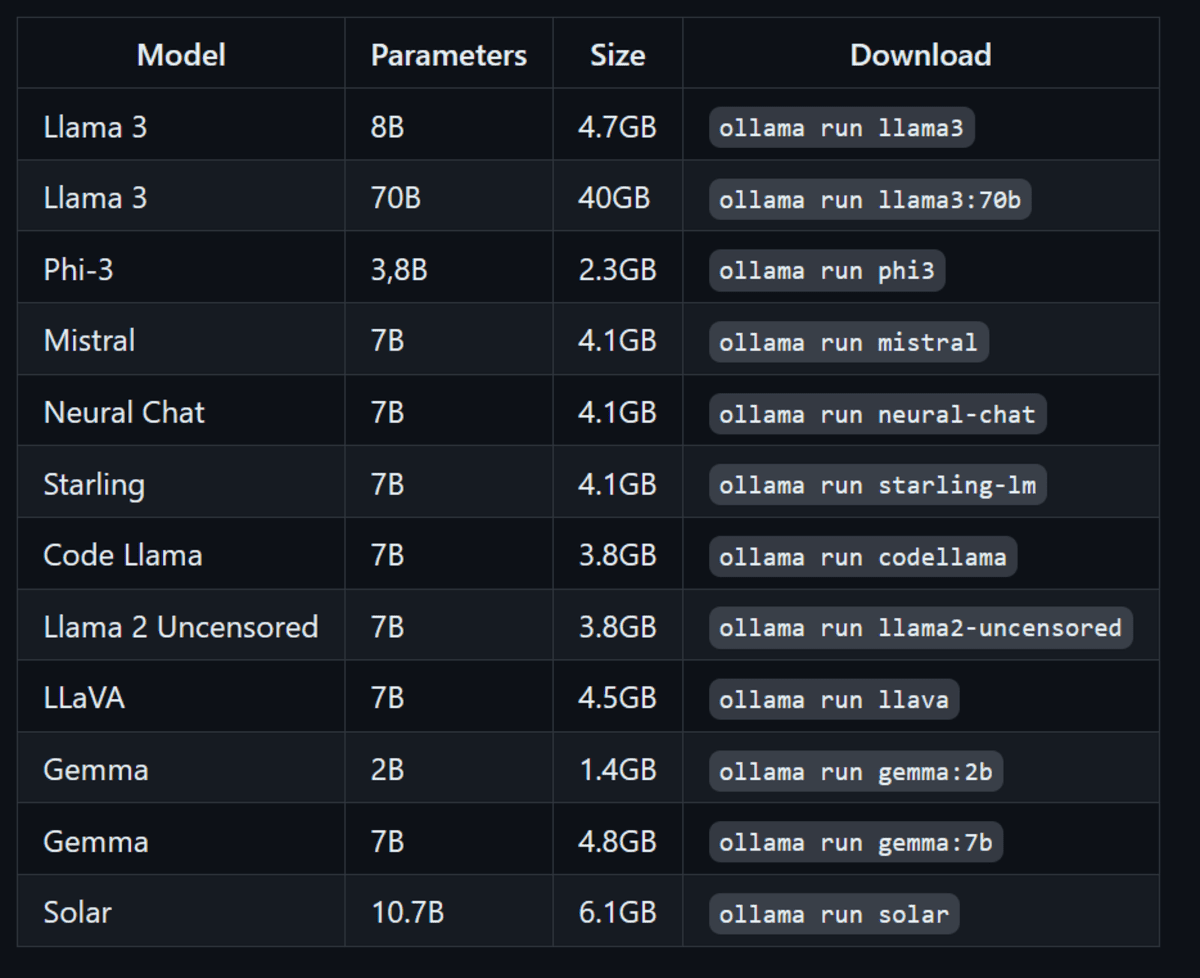 Image from ollama/ollama | Running other LLMs using Ollama
Image from ollama/ollama | Running other LLMs using Ollama
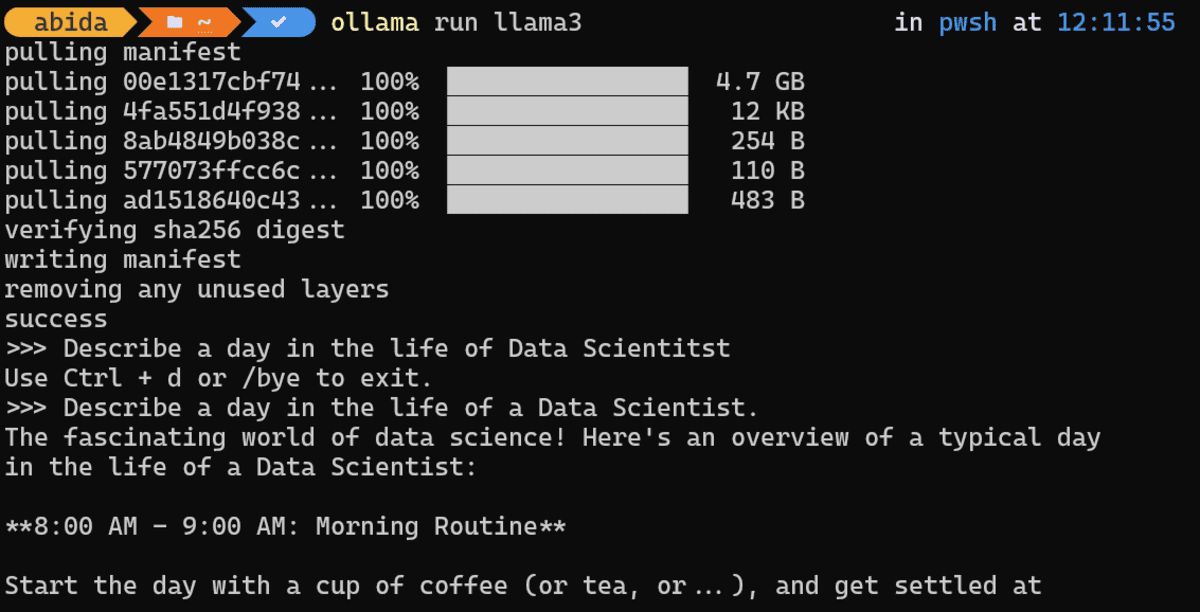
As soon as downloading is completed, you will be able to use the LLama 3 locally as if you are using it online.
Prompt: “Describe a day in the life of a Data Scientist.”
To demonstrate how fast the response generation is, I have attached the GIF of Ollama generating Python code and then explaining it.
Note: If you have Nvidia GPU on your laptop and CUDA installed, Ollama will automatically use GPU instead of CPU to generate a response. Which is 10 better.
Prompt: “Write a Python code for building the digital clock.”
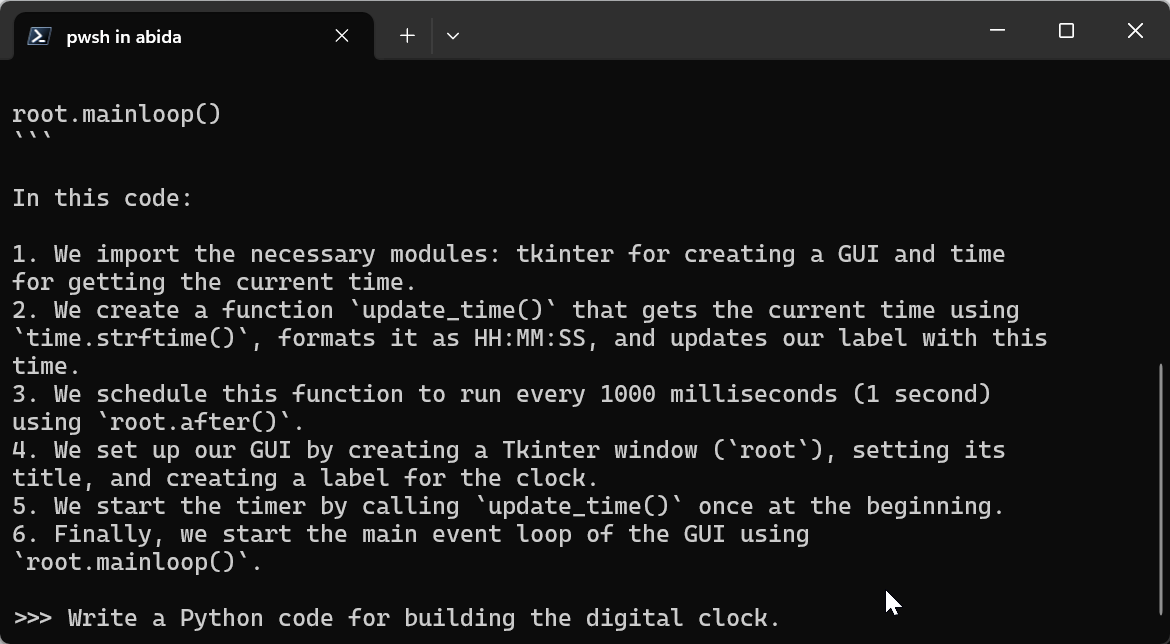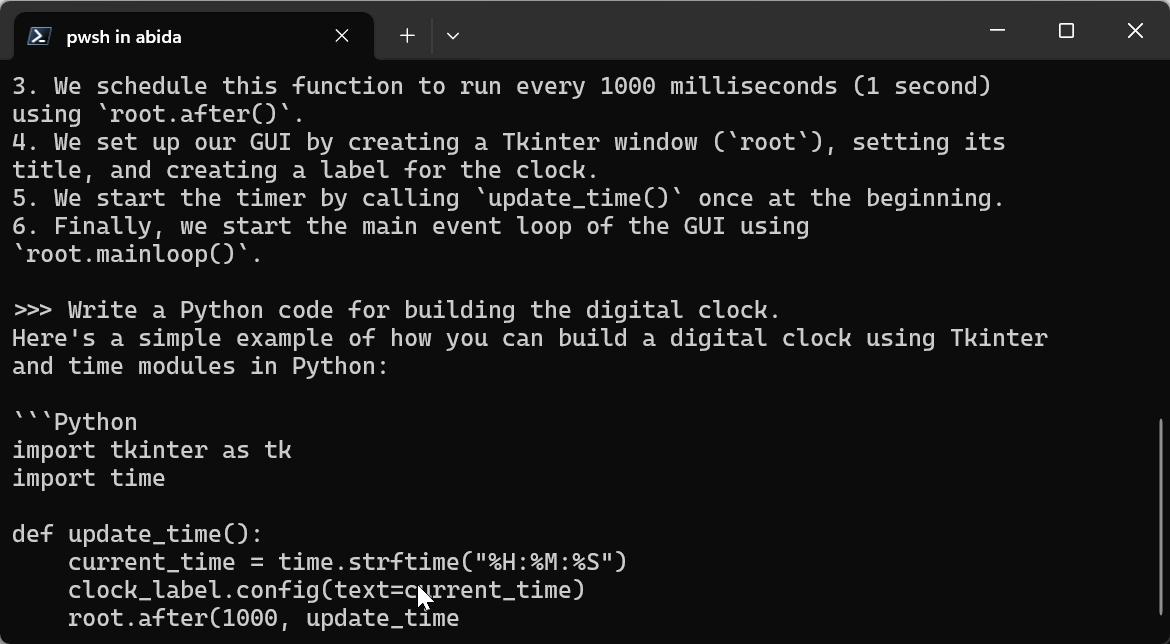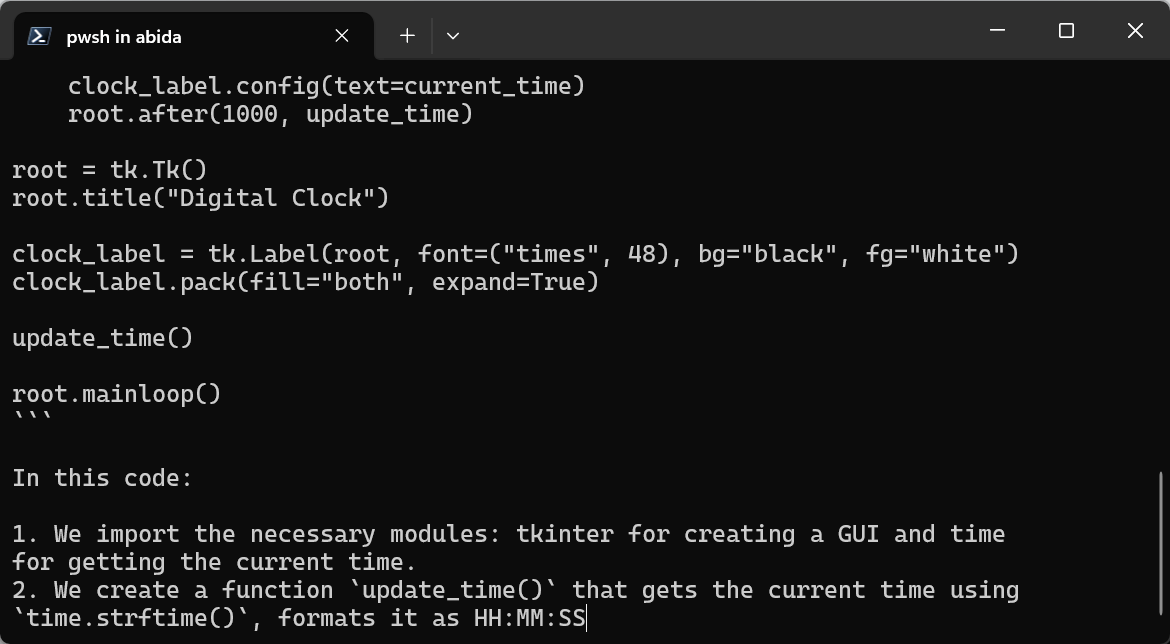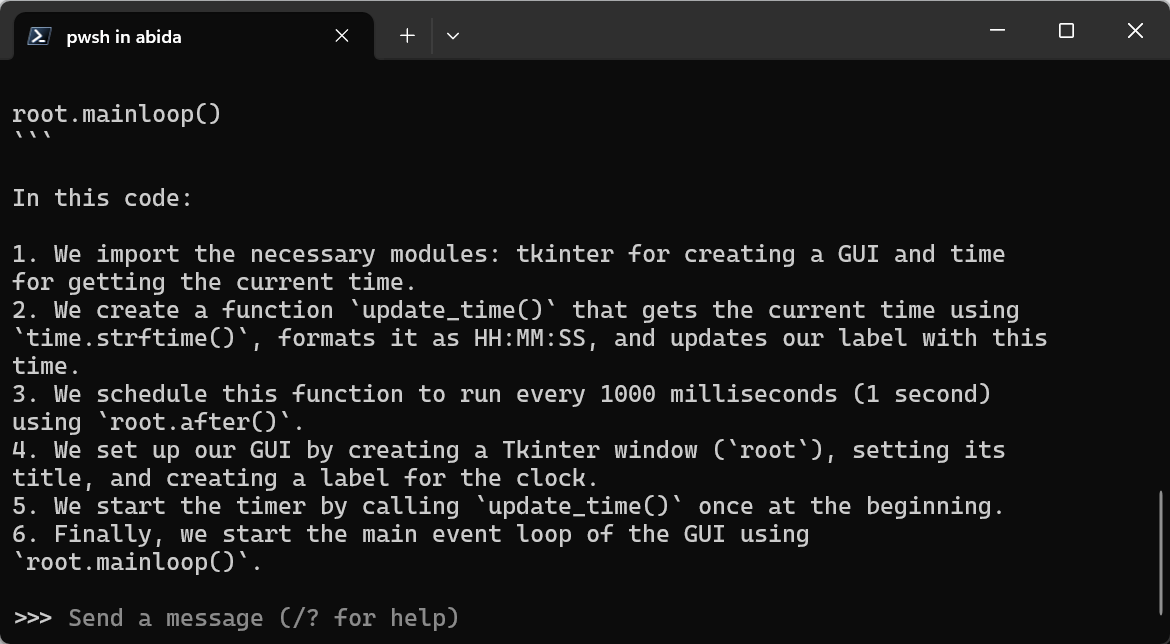
You can exit the chat by typing /bye and then start again by typing ollama run llama3.
Final Thoughts
Open-source frameworks and models have made AI and LLMs accessible to everyone. Instead of being controlled by a few corporations, these locally run tools like Ollama make AI available to anyone with a laptop.
Using LLMs locally provides privacy, security, and more control over response generation. Moreover, you don’t have to pay to use any service. You can even create your own AI-powered coding assistant and use it in VSCode.
If you want to learn about other applications to run LLMs locally, then you should read 5 Ways To Use LLMs On Your Laptop.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in technology management and a bachelor’s degree in telecommunication engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.






















{kind=link}