In our rapidly evolving digital world, the demand for instant gratification has never been higher. Whether we’re searching for information, products, or services, we expect our queries to be answered with lightning speed and pinpoint accuracy. However, the quest for speed and precision often presents a formidable challenge for modern search engines.
Traditional retrieval models face a fundamental trade-off: the more accurate they are, the higher the computational cost and latency. This latency can be a deal-breaker, negatively impacting user satisfaction, revenue, and energy efficiency. Researchers have been grappling with this conundrum, seeking ways to deliver both effectiveness and efficiency in a single package.
In a groundbreaking study, a team of researchers from the University of Glasgow has unveiled an ingenious solution that harnesses the power of smaller, more efficient transformer models to achieve lightning-fast retrieval without sacrificing accuracy. Meet shallow Cross-Encoders: a novel AI approach that promises to revolutionize the search experience.
Shallow Cross-Encoders are based on transformer models with fewer layers and reduced computational requirements. Unlike their larger counterparts, such as BERT or T5, these handy models can estimate the relevance of more documents within the same time budget, potentially leading to better overall effectiveness in low-latency scenarios.
But training these smaller models effectively is no easy feat. Conventional techniques often result in overconfidence and instability, hampering performance. To overcome this challenge, the researchers introduced an ingenious training scheme called gBCE (Generalized Binary Cross-Entropy), which mitigates the overconfidence problem and ensures stable, accurate results.
The gBCE training scheme incorporates two key components: (1) an increased number of negative samples per positive instance and (2) the gBCE loss function, which counters the effects of negative sampling. By carefully balancing these elements, the researchers were able to train highly effective shallow Cross-Encoders that consistently outperformed their larger counterparts in low-latency scenarios.
In a series of rigorous experiments, the researchers evaluated a range of shallow Cross-Encoder models, including TinyBERT (2 layers), MiniBERT (4 layers), and SmallBERT (4 layers), against full-size baselines like MonoBERT-Large and MonoT5-Base. The outcome was exceedingly impressive.
On the TREC DL 2019 dataset, the diminutive TinyBERT-gBCE model achieved an NDCG@10 score of 0.652 when the latency was limited to a mere 25 milliseconds – a staggering 51% improvement over the much larger MonoBERT-Large model (NDCG@10 of 0.431) under the same latency constraint.
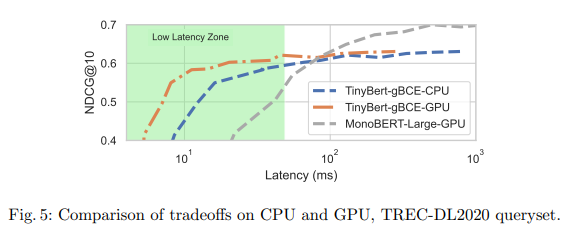
However, the advantages of shallow cross-encoders extend beyond sheer speed and accuracy. These compact models also offer significant benefits in terms of energy efficiency and cost-effectiveness. With their modest memory footprints, they can be deployed on a wide range of devices, from powerful data centers to resource-constrained edge devices, without the need for specialized hardware acceleration.
Imagine a world where your search queries are answered with lightning speed and pinpoint accuracy, whether you’re using a high-end workstation or a modest mobile device. This is the promise of shallow Cross-Encoders, a game-changing solution that could redefine the search experience for billions of users worldwide.
As the research team continue to refine and optimize this groundbreaking technology, we can look forward to a future where the trade-off between speed and accuracy becomes a thing of the past. With shallow Cross-Encoders at the forefront, the pursuit of instantaneous, accurate search results is no longer a distant dream – it’s a tangible reality within our grasp.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter.
Don’t Forget to join our 39k+ ML SubReddit
![]()
Vibhanshu Patidar is a consulting intern at MarktechPost. Currently pursuing B.S. at Indian Institute of Technology (IIT) Kanpur. He is a Robotics and Machine Learning enthusiast with a knack for unraveling the complexities of algorithms that bridge theory and practical applications.