
CodeCompose, an AI-powered code authoring tool utilized by tens of thousands of developers at Meta, has undergone scaling from providing single-line to multiline suggestions. This transition involved addressing unique challenges to enhance usability. Initially, multi-line suggestions were found to disrupt workflow by constantly shifting around existing code, potentially decreasing productivity and satisfaction. Additionally, generating multi-line suggestions took considerably longer, prompting investments to mitigate perceived latency.
Through model-hosting optimizations, the latency for multi-line suggestions was improved by 2.5 times. Subsequent experiments involving tens of thousands of engineers demonstrated that multi-line suggestions accounted for a significant portion of accepted characters and nearly doubled the percentage of keystrokes saved compared to single-line suggestions. Despite this, less than 1% of engineers at Meta opted out of multi-line suggestions after its rollout.
CodeCompose provides inline suggestions as a software engineer types code, but it was originally only designed to predict tokens that would complete the current line. Such single-line suggestions should be quick, highly accurate, and help with the immediate context.
CodeCompose’s multi-line algorithm is designed to trigger automatically as the user types, while also being selective in choosing trigger points and limiting suggestions to the user’s current scope. Although generating accurate multi-line suggestions is more challenging, the scope-based algorithm allows for the display of suggestions that align with the user’s current thought process, aiding their train of thought without introducing unnecessary distractions.
System architecture of CodeCompose: Client editor that surface the suggestions, a language server to mediate requests with CodeCompose model service host. In the request “multi-line” flag is passed to the model service.
The authors addressed the following challenges in this paper:
Challenge 1: The Jarring Effect: The team devised a scope-based algorithm to address this challenge. The algorithm triggers multi-line suggestions exclusively when the cursor is positioned at the end of a scope. Suggestions remain visible until the end of the current block, and upon acceptance, the cursor automatically moves to the end of the suggested block.
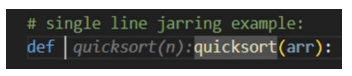
Single-line “jarring” effect example: The user cursor positioned between “def” keyword and the “quicksort” function, inline suggestion appears and moves the existing user code to the right.
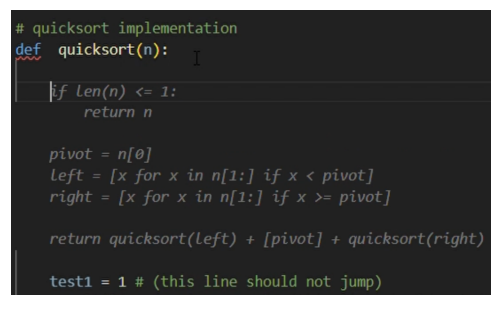
Example showing multi-line “jarring” effect: the user cursor was between a function name and the next line containing the statement “test1 = 1”. When the suggestion occurs, the existing line is pushed down, disrupting the developer’s flow and forcing them to review the suggested “quicksort” function while also determining the correct location of their existing code.
Challenge 2: Responsive UX: Recognizing that multi-line suggestions require more time to generate, efforts were made to minimize perceived user latency and enhance adoption compared to single-line suggestions. This involved (i) introducing a UI indicator to inform users when a multi-line suggestion is being generated and (ii) implementing optimizations in the model hosting service, such as Flash Attention and persistent K-V cache.
Challenge 3: Production Release Effectiveness: Throughout the rollout of multi-line suggestions, the team closely monitored various metrics including acceptance rate, display rate, latency, and throughput. This evaluation helped assess the overall effectiveness of multi-line suggestions compared to single-line suggestions.
Similar findings were observed, noted that although developers perceived an acceleration in coding, they often needed to allocate more time to review the generated code. Conversely, other studies indicated that generated suggestions facilitated the discovery of new APIs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter.
Don’t Forget to join our Telegram Channel
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.





















