
Developing and enhancing models capable of efficiently managing extensive sequential data is paramount in modern computational fields. This necessity is particularly critical in natural language processing, where models must process long text streams seamlessly, retaining context without compromising processing speed or accuracy. One of the key challenges within this scope is the traditional reliance on Transformer architectures, which, despite their broad adoption, suffer from quadratic computational complexity.
Existing research includes the Transformer architecture, which, despite its efficacy, suffers from high computational costs with longer sequences. Alternatives like linear attention mechanisms and state space models have been developed to reduce this cost, though often at the expense of performance. With its gated attention mechanism and exponential moving average, the LLAMA model and the MEGA architecture aim to address these limitations. However, these models still face challenges in scaling and efficiency, particularly in large-scale pretraining and handling extended data sequences.
Researchers from Meta, the University of Southern California, Carnegie Mellon University, and the University of California San Diego have introduced MEGALODON, a model designed to efficiently handle sequences of unlimited length—a capability that existing models struggle with. By integrating a Complex Exponential Moving Average (CEMA) and timestep normalization, MEGALODON offers reduced computational load and improved scalability, distinguishing itself from traditional Transformer models exhibiting quadratic computational growth with sequence length.
MEGALODON employs a combination of CEMA, timestep normalization, and a normalized attention mechanism. These technical components are crucial for modeling long sequences with high efficiency and low memory cost. The model has been rigorously tested on various language processing benchmarks, including multi-turn conversations, long-document comprehension, and extensive language modeling tasks. MEGALODON was benchmarked against datasets specifically designed for long-context scenarios, such as the Scrolls dataset for long-context QA tasks and PG19, which consists of long literary texts to demonstrate its efficacy and versatility.
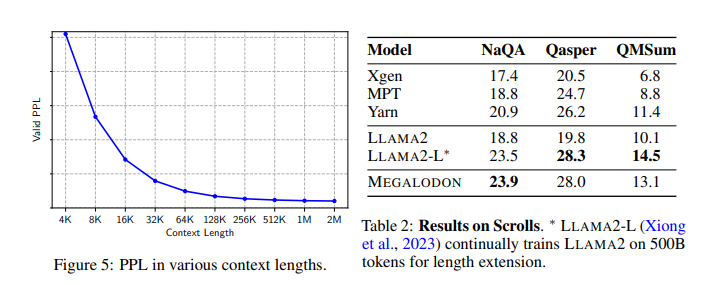
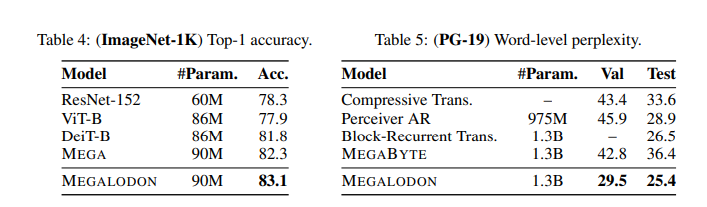
MEGALODON demonstrated quantifiable improvements in performance metrics. It recorded a training loss of 1.70, positioned between LLAMA2-7B, which registered a loss of 1.75, and LLAMA2-13B at 1.67. Regarding specific benchmarks, MEGALODON outperformed a standard Transformer model by achieving a lower perplexity rate on the Scrolls dataset, measuring at 23, compared to the Transformer’s 30. These results affirm MEGALODON‘s advanced processing capabilities for lengthy sequential data, substantiating its efficiency and effectiveness across varied linguistic tasks.
To conclude, the MEGALODON model marks a significant advancement in sequence modeling, addressing the inefficiencies of traditional Transformer architectures with innovative approaches like CEMA and timestep normalization. By achieving a training loss of 1.70 and demonstrating improved performance on challenging benchmarks such as the Scrolls dataset, MEGALODON proves its capability to handle extensive sequences effectively. This research enhances the processing of long data sequences and sets a new standard for future developments in natural language processing and related fields.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter.
Don’t Forget to join our 40k+ ML SubReddit
For Content Partnership, Please Fill Out This Form Here.
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.




















