
One of the most exciting developments in this field is the investigation of state-space models (SSMs) as an alternative to the widely used Transformer networks. These SSMs, distinguished by their innovative use of gating, convolutions, and input-dependent token selection, aim to overcome the computational inefficiencies posed by the quadratic cost of multi-head attention in Transformers. Despite their promising performance, SSMs’ in-context learning (ICL) capabilities have yet to be fully explored, especially compared to their Transformer counterparts.
The crux of this investigation lies in enhancing AI models’ ICL capabilities, a feature that allows them to learn new tasks through a few examples without the need for extensive parameter optimization. This capability is critical for developing more versatile and efficient AI systems. However, current models, especially those based on Transformer architectures, face scalability and computational demands challenges. These limitations necessitate exploring alternative models that can achieve similar or superior ICL performance without the associated computational burden.
Researchers from KRAFTON, Seoul National University, the University of Wisconsin-Madison, and the University of Michigan propose MambaFormer. This hybrid model represents a significant advancement in the field of in-context learning. This model ingeniously combines the strengths of Mamba SSMs with attention blocks from Transformer models, creating a powerful new architecture designed to outperform both in tasks where they falter. By eliminating the need for positional encodings and integrating the best features of SSMs and Transformers, MambaFormer offers a promising new direction for enhancing ICL capabilities in language models.
By focusing on a diverse set of ICL tasks, researchers could assess and compare the performance of SSMs, Transformer models, and the newly proposed hybrid model across various challenges. This comprehensive evaluation revealed that while SSMs and Transformers have strengths, they also possess limitations that can hinder their performance in certain ICL tasks. MambaFormer’s hybrid architecture was designed to address these shortcomings, leveraging the combined strengths of its constituent models to achieve superior performance across a broad spectrum of tasks.
In tasks where traditional SSMs and Transformer models struggled, such as sparse parity learning and complex retrieval functionalities, MambaFormer demonstrated remarkable proficiency. This performance highlights the model’s versatility and efficiency and underscores the potential of hybrid architectures to overcome the limitations of existing AI models. MambaFormer’s ability to excel in a wide range of ICL tasks without needing positional encodings marks a significant step forward in developing more adaptable and efficient AI systems.
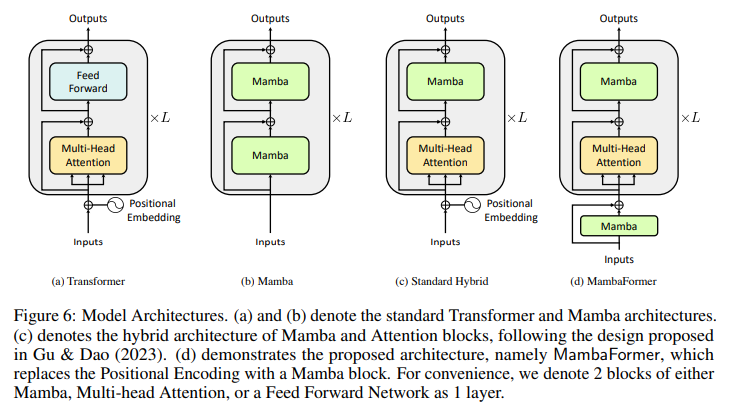
Reflecting on the contributions of this research, several key insights emerge:
The development of MambaFormer illustrates the immense potential of hybrid models in advancing the field of in-context learning. By combining the strengths of SSMs and Transformer models, MambaFormer addresses the limitations of each, offering a versatile and powerful new tool for AI research.
MambaFormer’s performance across diverse ICL tasks showcases the model’s efficiency and adaptability. This confirms the importance of innovative architectural designs in creating AI systems.
The success of MambaFormer opens new avenues for research, particularly in exploring how hybrid architectures can be further optimized for in-context learning. The findings also suggest the potential for these models to transform other areas of AI beyond language modeling.
In conclusion, the research on MambaFormer illuminates the unexplored potential of hybrid models in AI and sets a new benchmark for in-context learning. As AI continues to evolve, exploring innovative models like MambaFormer will be crucial in overcoming the challenges faced by current technologies and unlocking new possibilities for the future of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel




















