
Multimodal machine learning is an advanced research field that combines various data types, such as text, images, and audio, to create more comprehensive and accurate models. By integrating these different modalities, researchers aim to enhance the model’s ability to understand and reason about complex tasks. This integration allows models to leverage the strengths of each modality, leading to improved performance in applications ranging from image recognition and NLP to video analysis and beyond.
The main issue in multimodal machine learning is the inefficiency and inflexibility of large multimodal models (LMMs) when handling high-resolution images and videos. Traditional LMMs, like LLaVA, use a fixed number of visual tokens to represent an image, often resulting in an excessive number of tokens for dense visual content. This increases computational costs and degrades performance by overwhelming the model with too much information. Therefore, there is a critical need for methods that can dynamically adjust the number of tokens based on the complexity of the visual input.
Existing solutions to this problem, such as token pruning and merging, aim to reduce the number of visual tokens fed into the language model. However, these methods typically generate a fixed-length output for each image, which does not allow flexibility to balance information density and efficiency. They need to adapt to varying levels of visual complexity, which can be critical in applications like video analysis, where the visual content can significantly vary from frame to frame.
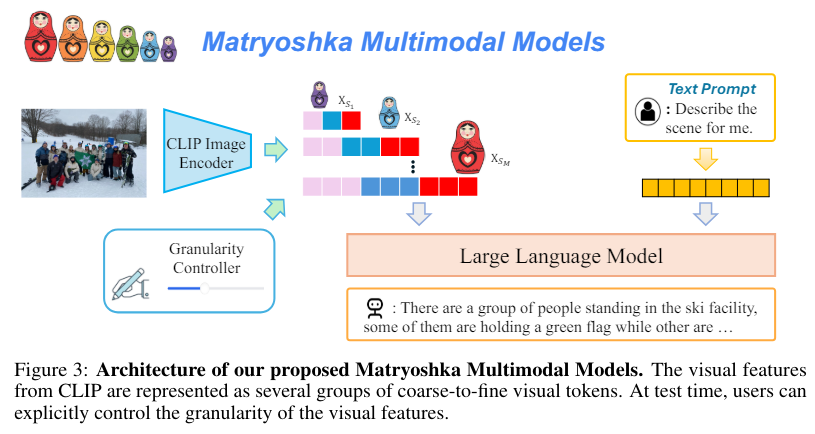
The University of Wisconsin-Madison and Microsoft Research researchers introduced Matryoshka Multimodal Models (M3). Inspired by the concept of Matryoshka dolls, M3 represents visual content as nested sets of visual tokens that capture information across multiple granularities. This novel approach allows for explicit control over the visual granularity during inference, enabling the adjustment of the number of tokens based on the anticipated complexity or simplicity of the content. For example, an image with dense details can be represented with more tokens, while simpler images can use fewer tokens.
The M3 model achieves this by encoding images into multiple sets of visual tokens with increasing granularity levels, from coarse to fine. During training, the model learns to derive coarser tokens from finer ones, ensuring that the visual information is captured efficiently. Specifically, the model uses scales such as 1, 9, 36, 144, and 576 tokens, with each level providing a progressively finer representation of the visual content. This hierarchical structure allows the model to preserve spatial information while adapting the level of detail based on the specific requirements.
Performance evaluations of the M3 model demonstrate its significant advantages. On COCO-style benchmarks, the model achieved accuracy similar to using all 576 tokens with only about 9 per image. This represents a substantial improvement in efficiency without compromising accuracy. The M3 model also performed well on other benchmarks, showing it can maintain high performance even with a drastically reduced number of tokens. For instance, the model’s accuracy with 9 tokens was comparable to Qwen-VL-Chat with 256 tokens, and in some cases, it achieved similar performance with just 1 token.
The model can adapt to different computational and memory constraints during deployment by allowing for flexible control over the number of visual tokens. This flexibility is particularly valuable in real-world applications where resources may be limited. The M3 approach also provides a framework for evaluating the visual complexity of datasets, helping researchers understand the optimal granularity needed for various tasks. For example, while natural scene benchmarks like COCO can be handled with around 9 tokens, dense visual perception tasks such as document understanding or OCR require more tokens, ranging from 144 to 576.

In conclusion, Matryoshka Multimodal Models (M3) address the inefficiencies of current LMMs and provide a flexible, adaptive method for representing visual content, setting the stage for more efficient and effective multimodal systems. The model’s ability to dynamically adjust the number of visual tokens based on content complexity ensures a better balance between performance and computational cost. This innovative approach enhances multimodal models’ understanding and reasoning capabilities and opens up new possibilities for their application in diverse and resource-constrained environments.
Check out the Paper and Project. All credit for this research goes to the researchers of this project.
Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter.
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.





















{kind=link}