In recent years, computational linguistics has witnessed significant advancements in developing language models (LMs) capable of processing multiple languages simultaneously. This evolution is crucial in today’s globalized world, where effective communication across diverse linguistic boundaries is essential. Multilingual Large Language Models (MLLMs) are at the forefront of this development, offering solutions that cater to the complex needs of multilingual understanding and generation.
The primary challenge that MLLMs address is the effective processing and generation of text across various languages, including those with limited resources. Traditionally, LMs have been predominantly developed for high-resource languages, such as English, which has left a gap in technology applicable to the broader linguistic spectrum. This issue is particularly acute in low-resource scenarios where data scarcity significantly impedes the performance of conventional models.
Current methods have relied heavily on massive multilingual datasets that cover several languages to pre-train these models. This approach aims to inspire the models with a fundamental understanding of linguistic structures and vocabularies across languages. However, these models often require further fine-tuning on task-specific datasets to optimize their functionality for particular applications, which can be resource-intensive and inefficient.
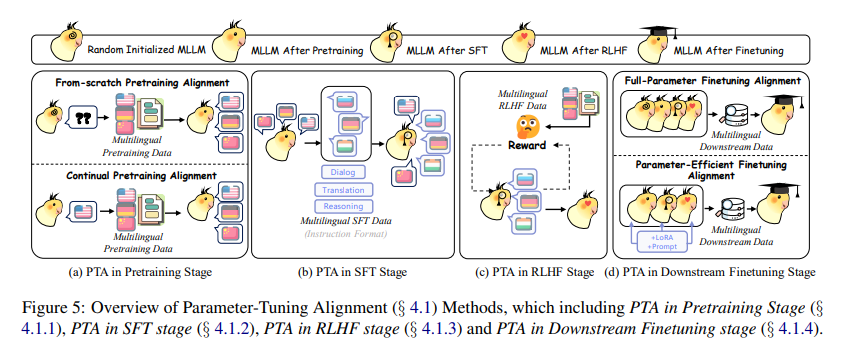
Recent reviews by researchers from Central South University, Harbin Institute of Technology, Shanghai AI Laboratory, Tsinghua University, Singapore Management University, and University of Illinois at Chicago have studied innovative methods that streamline adapting LMs to handle multiple languages more effectively. These methods utilize a combination of parameter-tuning and parameter-freezing techniques. Parameter-tuning involves adjusting the model’s internal settings to align with the multilingual data during the pre-training and fine-tuning phases. Parameter-freezing allows the model to adapt to new languages by locking certain parameters while adjusting others and facilitating quicker adaptation with less computational overhead.
The technical specifics of reviewed methods show that parameter-tuning strategies, such as aligning multilingual embeddings during the pre-training stage, have been applied to various language pairs, enhancing the models’ ability to handle cross-lingual tasks. For instance, recent models have demonstrated improvements in bilingual task performance by up to 15% compared to traditional monolingual models. Parameter-freezing techniques have shown the potential to reduce the time required for model adaptation by approximately 20%.
The empirical results discussed, for example, models utilizing these new methods, have shown enhanced accuracy in text generation and translation tasks across multiple languages, particularly in scenarios involving underrepresented languages. This improvement is crucial for applications such as automated translation services, content creation, and international communication platforms, where linguistic diversity is a common challenge.
Review Snapshot

In conclusion, the advancement of MLLMs represents a significant step forward in AI and computational linguistics. By incorporating innovative alignment strategies and efficient parameter adjustments, these models are set to revolutionize how to interact with technology across language barriers. The increased effectiveness in handling diverse linguistic inputs improves the usability of LMs in multilingual settings and paves the way for further innovations in this rapidly evolving field. Integrating these models into practical applications continues to enhance their relevance and impact.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter.
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.