
In this post, we will explore the new state-of-the-art open-source model called Mixtral 8x7b. We will also learn how to access it using the LLaMA C++ library and how to run large language models on reduced computing and memory.
Mixtral 8x7b is a high-quality sparse mixture of experts (SMoE) model with open weights, created by Mistral AI. It is licensed under Apache 2.0 and outperforms Llama 2 70B on most benchmarks while having 6x faster inference. Mixtral matches or beats GPT3.5 on most standard benchmarks and is the best open-weight model regarding cost/performance.
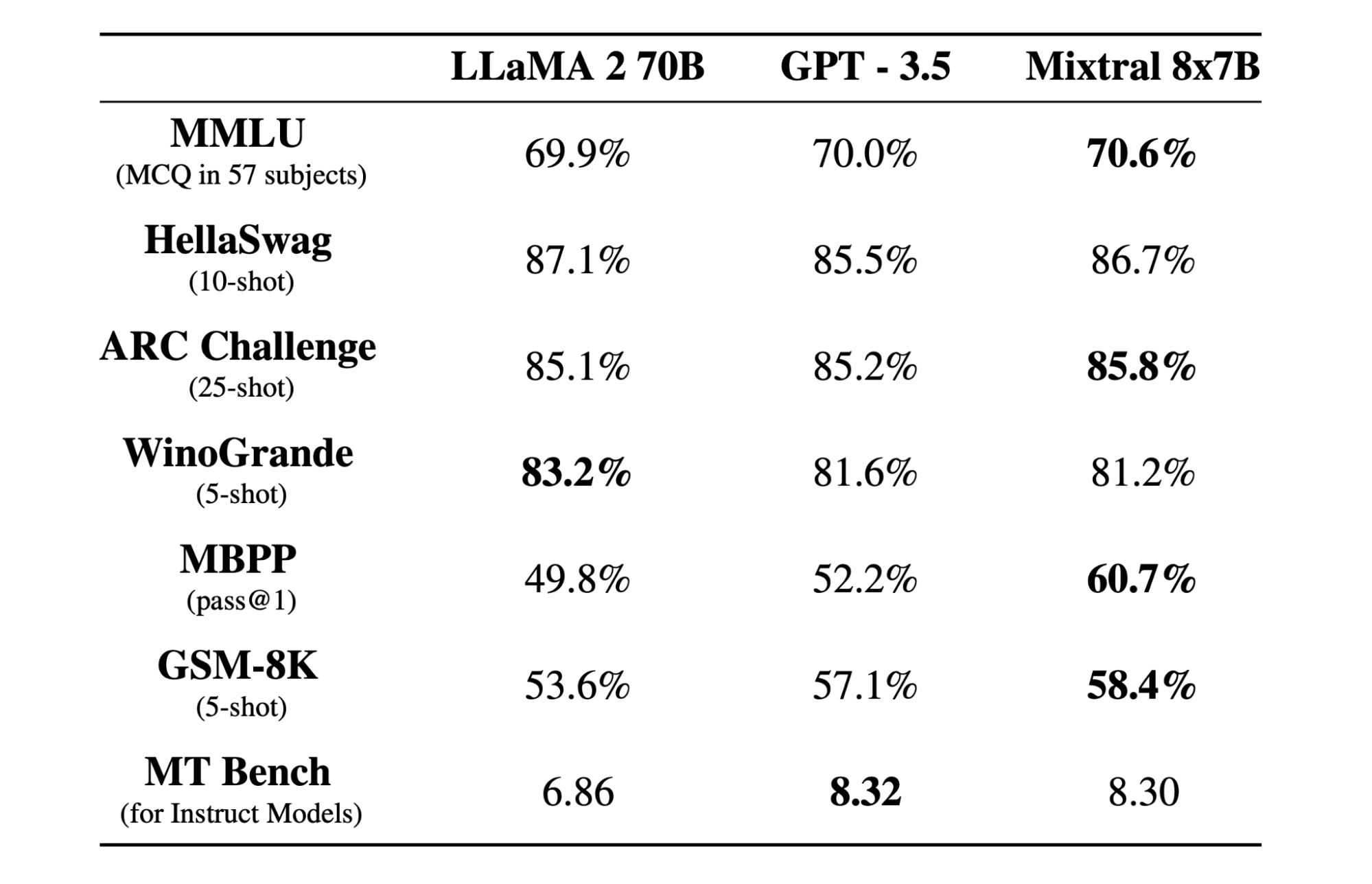 Image from Mixtral of experts
Image from Mixtral of experts
Mixtral 8x7B uses a decoder-only sparse mixture-of-experts network. This involves a feedforward block selecting from 8 groups of parameters, with a router network choosing two of these groups for each token, combining their outputs additively. This method enhances the model’s parameter count while managing cost and latency, making it as efficient as a 12.9B model, despite having 46.7B total parameters.
Mixtral 8x7B model excels in handling a wide context of 32k tokens and supports multiple languages, including English, French, Italian, German, and Spanish. It demonstrates strong performance in code generation and can be fine-tuned into an instruction-following model, achieving high scores on benchmarks like MT-Bench.
LLaMA.cpp is a C/C++ library that provides a high-performance interface for large language models (LLMs) based on Facebook’s LLM architecture. It is a lightweight and efficient library that can be used for a variety of tasks, including text generation, translation, and question answering. LLaMA.cpp supports a wide range of LLMs, including LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B, and GPT4ALL. It is compatible with all operating systems and can function on both CPUs and GPUs.
In this section, we will be running the llama.cpp web application on Colab. By writing a few lines of code, you will be able to experience the new state-of-the-art model performance on your PC or on Google Colab.
Getting Started
First, we will download the llama.cpp GitHub repository using the command line below:
After that, we will change directory into the repository and install the llama.cpp using the `make` command. We are installing the llama.cpp for the NVidia GPU with CUDA installed.
!make LLAMA_CUBLAS=1
Download the Model
We can download the model from the Hugging Face Hub by selecting the appropriate version of the `.gguf` model file. More information on various versions can be found in TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
 Image from TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Image from TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
You can use the command `wget` to download the model in the current directory.
External Address for LLaMA Server
When we run the LLaMA server it will give us a localhost IP which is useless for us on Colab. We need the connection to the localhost proxy by using the Colab kernel proxy port.
After running the code below, you will get the global hyperlink. We will use this link to access our webapp later.
print(eval_js(“google.colab.kernel.proxyPort(6589)”))
Running the Server
To run the LLaMA C++ server, you need to provide the server command with the location of the model file and the correct port number. It’s important to make sure that the port number matches the one we initiated in the previous step for the proxy port.























{kind=link}