
Apache Iceberg’s ecosystem of diverse adopters, contributors and commercial support continues to grow, establishing itself as the industry standard table format for an open data lakehouse architecture. Snowflake’s support for Iceberg Tables is now in public preview, helping customers build and integrate Snowflake into their lake architecture.
In this blog post, we’ll dive deeper into the considerations for selecting an Iceberg Table catalog and how catalog conversion works
Choosing an Iceberg Table catalog
To give customers flexibility for how they fit Snowflake into their architecture, Iceberg Tables can be configured to use either Snowflake or an external service as the table’s catalog to track metadata. With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloud storage location. With these three options, which one should you use?
Are you using Snowflake on AWS and already using Glue Data Catalog for your data lake? If so, then the GLUE catalog integration provides an easy way to start querying those tables with Snowflake. Your other engines that may be writing to the table, such as Apache Spark or Apache Flink, can continue to write, and Snowflake can read. A benefit of the GLUE catalog integration in comparison to OBJECT_STORE is easier table refresh since GLUE doesn’t require a specific metadata file path, while OBJECT_STORE does.
Are you using Snowflake on Azure or GCP and only need Snowflake as a query engine without full read-and-write? In this case, you can integrate Snowflake using the OBJECT_STORE catalog integration. Just like GLUE, your other engines that may be writing to the table, such as Apache Spark or Apache Flink, can continue to write, and Snowflake can read.
Are you not already using any Iceberg catalog? Or do you need full read-and-write from Snowflake? If so, then an Iceberg Table using SNOWFLAKE as the catalog source is ideal. As a fully managed service, Snowflake has built-in features that provide you with high availability across cloud availability zones, which also extends to the Snowflake-managed Iceberg catalog. Spark-based tools, even running on clusters in different clouds or regions, can read the table using the Snowflake Iceberg catalog SDK, which you can learn more about in our documentation.
Are you already using Iceberg and want to start using Snowflake as the table catalog? For this case, we’ve added a simple SQL command that converts an Iceberg Table’s catalog source from GLUE or OBJECT_STORE to SNOWFLAKE without any movement, copying or rewriting of files, making it easy and inexpensive to onboard. Regardless of the chosen Iceberg catalog, all data resides in customers’ cloud storage in open formats, giving them full control.
How catalog conversion works
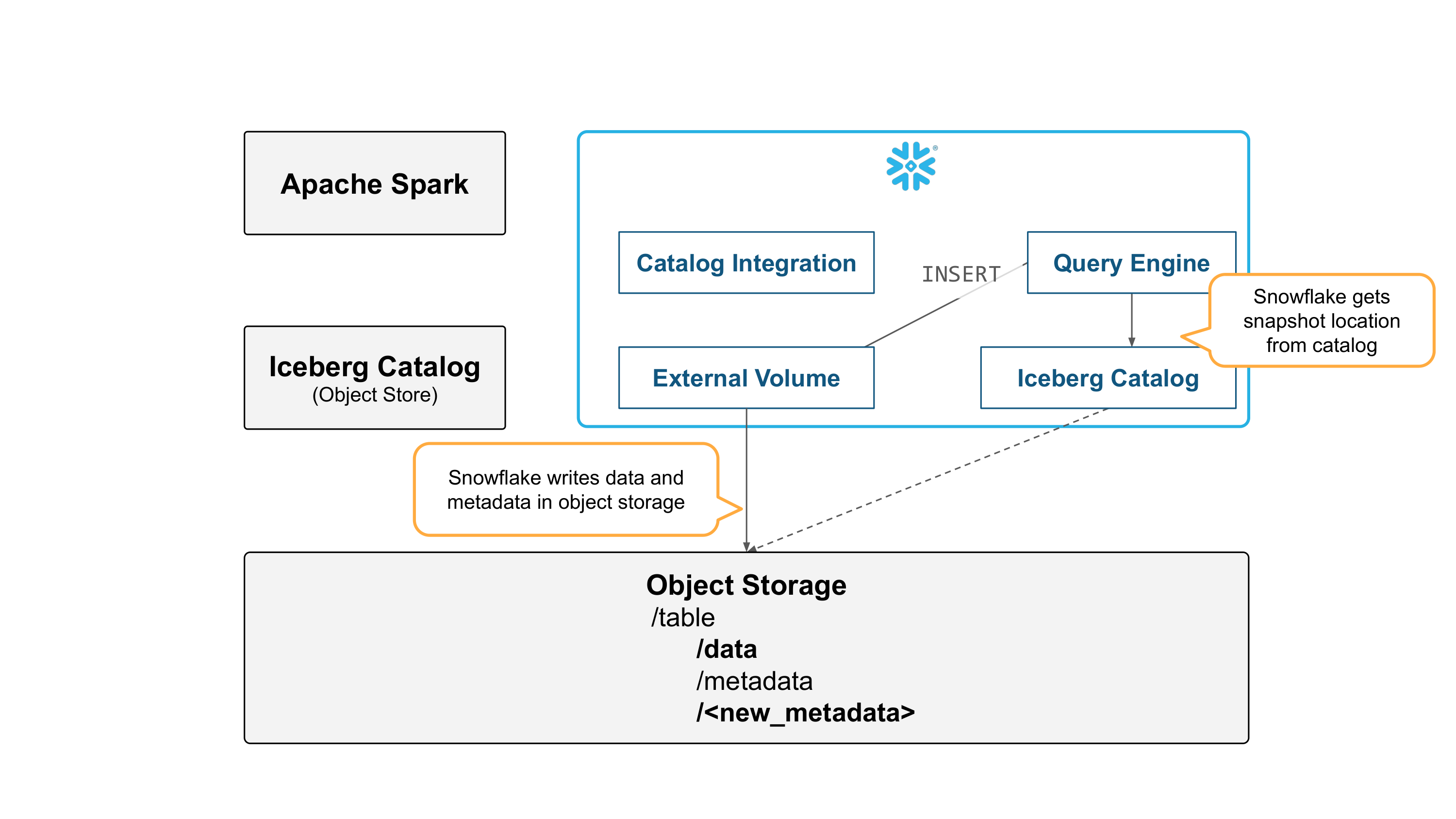
To see exactly how catalog conversion works, let’s walk through the process step-by-step. Suppose you use Spark to initially create and load data to an Iceberg table.
Now in public preview, you can query those tables from Snowflake by integrating with the catalog (catalog integration) and object storage (external volume).

If you convert the table’s catalog to Snowflake, no Parquet data files are moved or rewritten. Snowflake only generates metadata, making this an inexpensive operation in comparison to a full copy or rewrite of the table.

Now, Snowflake can make changes to the table.
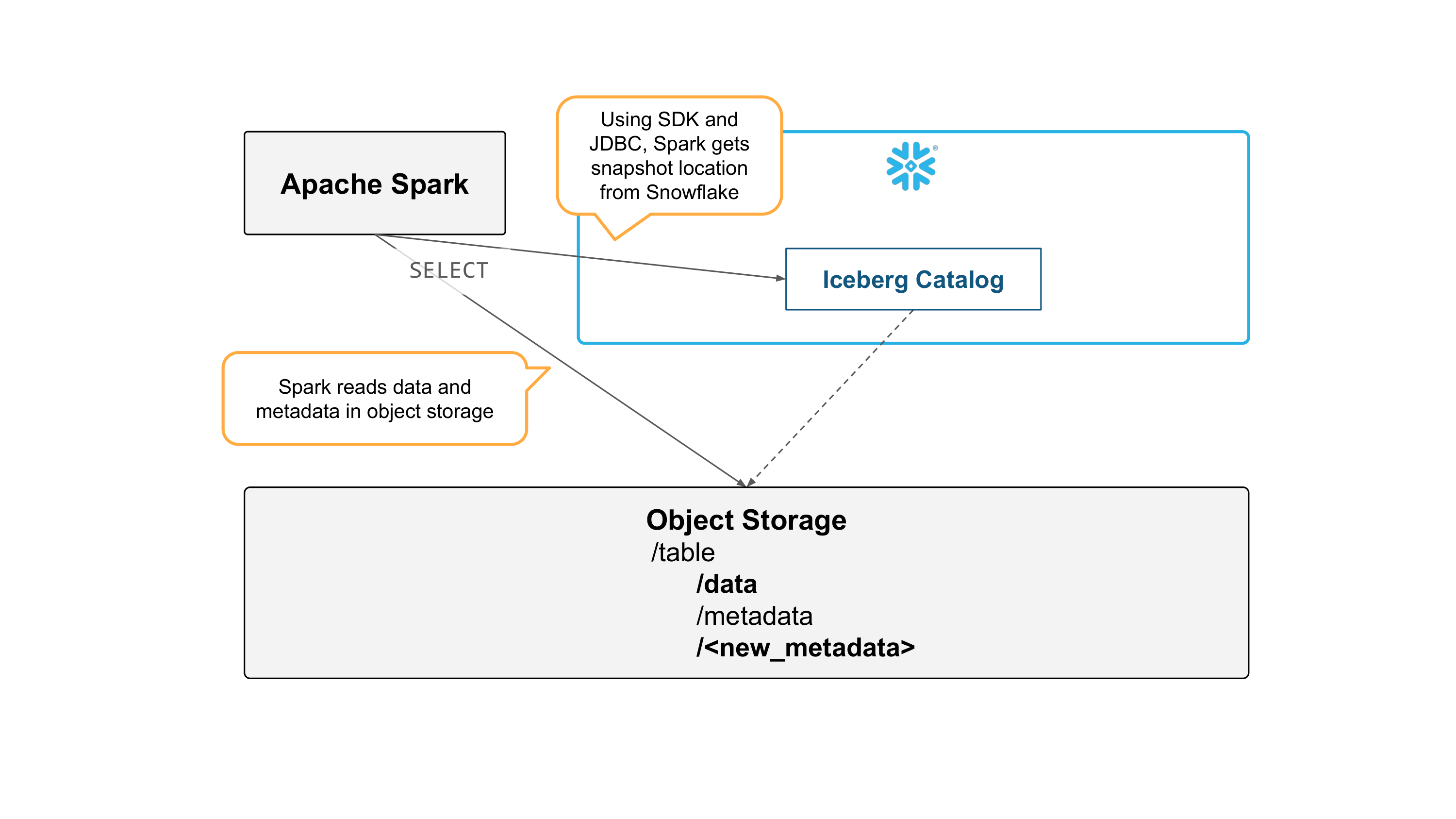
Spark can read the table by getting snapshot information from Snowflake, and reading metadata and data files directly from object storage.
Try it out
Iceberg Tables are supported in all cloud regions except SnowGov regions. If you’d like to try Iceberg Tables, you can get started today by following this quickstart guide. If you’d prefer an instructor-led lab, sign up for a free virtual hands-on lab to be held on January 10, 2024. For more detailed information, please refer to our documentation.
The post Build an Open Data Lakehouse with Iceberg Tables, Now in Public Preview appeared first on Snowflake.






















{kind=link}