
This article will delve into what RAG promises and its practical reality. We’ll explore how RAG works, its potential benefits, and then share firsthand accounts of the challenges we’ve encountered, the solutions we’ve developed, and the unresolved questions we continue to investigate. Through this, you’ll gain a comprehensive understanding of RAG’s capabilities and its evolving role in advancing AI.
Imagine you’re chatting with someone who’s not only out of touch with current events but also prone to confidently making things up when they’re unsure. This scenario mirrors the challenges with traditional generative AI: while knowledgeable, it relies on outdated data and often “hallucinates” details, leading to errors delivered with unwarranted certainty.
Retrieval-augmented generation (RAG) transforms this scenario. It’s like giving that person a smartphone with access to the latest information from the Internet. RAG equips AI systems to fetch and integrate real-time data, enhancing the accuracy and relevance of their responses. However, this technology isn’t a one-stop solution; it navigates uncharted waters with no uniform strategy for all scenarios. Effective implementation varies by use case and often requires navigating through trial and error.
What is RAG and How Does It Work?
Retrieval-augmented generation is an AI technique that promises to significantly enhance the capabilities of generative models by incorporating external, up-to-date information during the response generation process. This method equips AI systems to produce responses that are not only accurate but also highly relevant to current contexts, by enabling them to access the most recent data available.
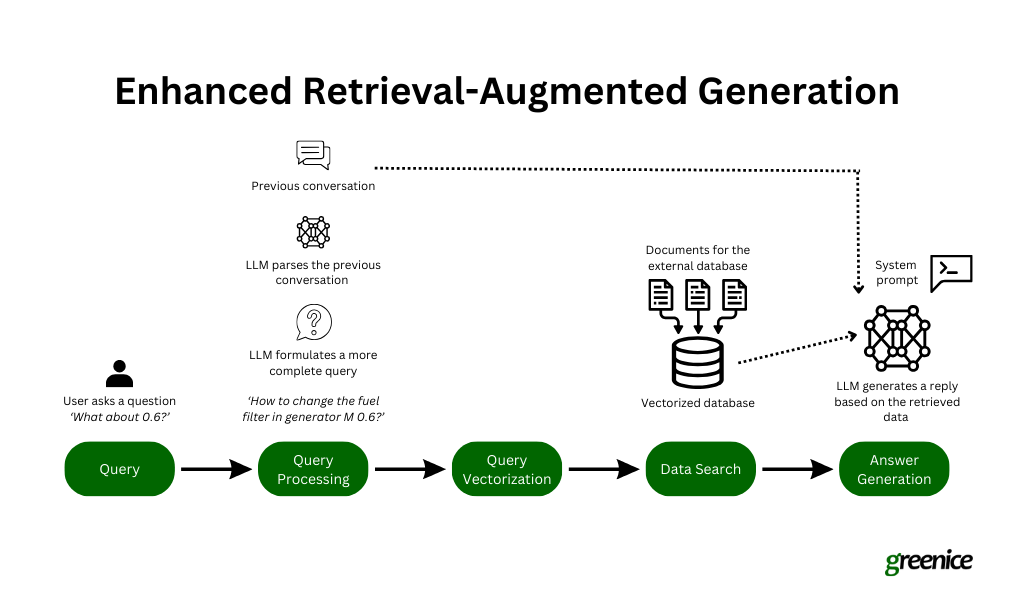
Here’s a detailed look at each step involved:
Initiating the query. The process starts when a user poses a question to an AI chatbot. This is the initial interaction, where the user brings a specific topic or query to the AI.
Encoding for retrieval. The query is then transformed into text embeddings. These embeddings are digital representations of the query that encapsulate the essence of the question in a format that the model can analyze computationally.
Finding relevant data. The retrieval component of RAG takes over, using the query embeddings to perform a semantic search across a dataset. This search is not about matching keywords but understanding the intent behind the query and finding data that aligns with this intent.
Generating the answer. With the relevant external data integrated, the RAG generator crafts a response that combines the AI’s trained knowledge with the newly retrieved, specific information. This results in a response that is not only informed but also contextually relevant.
Image source
RAG Development Process
Developing a retrieval-augmented generation system for generative AI involves several key steps to ensure it not only retrieves relevant information but also integrates it effectively to enhance responses. Here’s a streamlined overview of the process:
Collecting custom data. The first step is gathering the external data your AI will access. This involves compiling a diverse and relevant dataset that corresponds to the topics the AI will address. Sources might include textbooks, equipment manuals, statistical data, and project documentation to form the factual basis for the AI’s responses.
Chunking and formatting data. Once collected, the data needs preparation. Chunking breaks down large datasets into smaller, more manageable segments for easier processing.
Converting data to embeddings (vectors). This involves converting the data chunks into embeddings, also called vectors — dense numerical representations that help the AI analyze and compare data efficiently.
Developing the data search. The system uses advanced search algorithms, including semantic search, to go beyond mere keyword matching. It uses natural-language processing (NLP) to grasp the intent behind queries and retrieve the most relevant data, even if the user’s terminology isn’t precise.
Preparing system prompts. The final step involves crafting prompts that guide how the large language model (LLM) uses the retrieved data to formulate responses. These prompts help ensure that the AI’s output is not only informative but also contextually aligned with the user’s query.
These steps outline the ideal process for RAG development. However, practical implementation often requires additional adjustments and optimizations to meet specific project goals, as challenges can arise at any stage of the process.
The Promises of RAG
RAG’s promises are twofold. On the one hand, it aims to simplify how users find answers, enhancing their experience by providing more accurate and relevant responses. This improves the overall process, making it easier and more intuitive for users to get the information they need. On the other hand, RAG enables businesses to fully exploit their data by making vast stores of information readily searchable, which can lead to better decision-making and insights.
Accuracy boost
Accuracy remains a critical limitation in large language models), which can manifest in several ways:
False information. When unsure, LLMs might present plausible but incorrect information.
Outdated or generic responses. Users looking for specific and current information often receive broad or outdated answers.
Non-authoritative sources. LLMs sometimes generate responses based on unreliable sources.
Terminology confusion. Different sources may use similar terminology in diverse contexts, leading to inaccurate or confused responses.
With RAG, you can tailor the model to draw from the right data, ensuring that responses are both relevant and accurate for the tasks at hand.
Conversational search
RAG is set to enhance how we search for information, aiming to outperform traditional search engines like Google by allowing users to find necessary information through a human-like conversation rather than a series of disconnected search queries. This promises a smoother and more natural interaction, where the AI understands and responds to queries within the flow of a normal dialogue.
Reality check
However appealing the promises of RAG might seem, it’s important to remember that this technology is not a cure-all. While RAG can offer undeniable benefits, it’s not the answer to all challenges. We’ve implemented the technology in several projects, and we’ll share our experiences, including the obstacles we’ve faced and the solutions we’ve found. This real-world insight aims to provide a balanced view of what RAG can truly offer and what remains a work in progress.
Real-world RAG Challenges
Implementing retrieval-augmented generation in real-world scenarios brings a unique set of challenges that can deeply impact AI performance. Although this method boosts the chances of accurate answers, perfect accuracy isn’t guaranteed.
Our experience with a power generator maintenance project showed significant hurdles in ensuring the AI used retrieved data correctly. Often, it would misinterpret or misapply information, resulting in misleading answers.
Additionally, handling conversational nuances, navigating extensive databases, and correcting AI “hallucinations” when it invents information complicate RAG deployment further.
These challenges highlight that RAG must be custom-fitted for each project, underscoring the continuous need for innovation and adaptation in AI development.
Accuracy is not guaranteed
While RAG significantly improves the odds of delivering the correct answer, it’s crucial to recognize that it doesn’t guarantee 100% accuracy.
In our practical applications, we’ve found that it’s not enough for the model to simply access the right information from the external data sources we’ve provided; it must also effectively utilize that information. Even when the model does use the retrieved data, there’s still a risk that it might misinterpret or distort this information, making it less useful or even inaccurate.
For example, when we developed an AI assistant for power generator maintenance, we struggled to get the model to find and use the right information. The AI would occasionally “spoil” the valuable data, either by misapplying it or altering it in ways that detracted from its utility.
This experience highlighted the complex nature of RAG implementation, where merely retrieving information is just the first step. The real task is integrating that information effectively and accurately into the AI’s responses.
Nuances of conversational search
There’s a big difference between searching for information using a search engine and chatting with a chatbot. When using a search engine, you usually make sure your question is well-defined to get the best results. But in a conversation with a chatbot, questions can be less formal and incomplete, like saying, “And what about X?” For example, in our project developing an AI assistant for power generator maintenance, a user might start by asking about one generator model and then suddenly switch to another one.
Handling these quick changes and abrupt questions requires the chatbot to understand the full context of the conversation, which is a major challenge. We found that RAG had a hard time finding the right information based on the ongoing conversation.
To improve this, we adapted our system to have the underlying LLM rephrase the user’s query using the context of the conversation before it tries to find information. This approach helped the chatbot to better understand and respond to incomplete questions and made the interactions more accurate and relevant, although it’s not perfect every time.
Database navigation
Navigating vast databases to retrieve the right information is a significant challenge in implementing RAG. Once we have a well-defined query and understand what information is needed, the next step isn’t just about searching; it’s about searching effectively. Our experience has shown that attempting to comb through an entire external database is not practical. If your project includes hundreds of documents, each potentially spanning hundreds of pages, the volume becomes unmanageable.
To address this, we’ve developed a method to streamline the process by first narrowing our focus to the specific document likely to contain the needed information. We use metadata to make this possible — assigning clear, descriptive titles and detailed descriptions to each document in our database. This metadata acts like a guide, helping the model to quickly identify and select the most relevant document in response to a user’s query.
Once the right document is pinpointed, we then perform a vector search within that document to locate the most pertinent section or data. This targeted approach not only speeds up the retrieval process but also significantly enhances the accuracy of the information retrieved, ensuring that the response generated by the AI is as relevant and precise as possible. This strategy of refining the search scope before delving into content retrieval is crucial for efficiently managing and navigating large databases in RAG systems.
Hallucinations
What happens if a user asks for information that isn’t available in the external database? Based on our experience, the LLM might invent responses. This issue — known as hallucination — is a significant challenge, and we’re still working on solutions.
For instance, in our power generator project, a user might inquire about a model that isn’t documented in our database. Ideally, the assistant should acknowledge the lack of information and state its inability to assist. However, instead of doing this, the LLM sometimes pulls information about a similar model and presents it as if it were relevant. As of now, we’re exploring ways to address this issue to ensure the AI reliably indicates when it cannot provide accurate information based on the data available.
Finding the “right” approach
Another crucial lesson from our work with RAG is that there’s no one-size-fits-all solution for its implementation. For example, the successful strategies we developed for the AI assistant in our power generator maintenance project did not translate directly to a different context.
We attempted to apply the same RAG setup to create an AI assistant for our sales team, aimed at streamlining onboarding and enhancing knowledge transfer. Like many other businesses, we struggle with a vast array of internal documentation that can be difficult to sift through. The goal was to deploy an AI assistant to make this wealth of information more accessible.
However, the nature of the sales documentation — geared more towards processes and protocols rather than technical specifications — differed significantly from the technical equipment manuals used in the previous project. This difference in content type and usage meant that the same RAG techniques did not perform as expected. The distinct characteristics of the sales documents required a different approach to how information was retrieved and presented by the AI.
This experience underscored the need to tailor RAG strategies specifically to the content, purpose, and user expectations of each new project, rather than relying on a universal template.
Key Takeaways and RAG’s Future
As we reflect on the journey through the challenges and intricacies of retrieval-augmented generation, several key lessons emerge that not only underscore the technology’s current capabilities but also hint at its evolving future.
Adaptability is crucial. The varied success of RAG across different projects demonstrates the necessity for adaptability in its application. A one-size-fits-all approach doesn’t suffice, due to the diverse nature of data and requirements in each project.
Continuous improvement. Implementing RAG requires ongoing adjustment and innovation. As we’ve seen, overcoming obstacles like hallucinations, improving conversational search, and refining data navigation are critical to harnessing RAG’s full potential.
Importance of data management. Effective data management, particularly in organizing and preparing data, proves to be a cornerstone for successful implementation. This includes meticulous attention to how data is chunked, formatted, and made searchable.
Looking Ahead: The Future of RAG
Enhanced contextual understanding. Future developments in RAG aim to better handle the nuances of conversation and context. Advances in NLP and machine learning could lead to more sophisticated models that understand and process user queries with greater precision.
Broader implementation. As businesses recognize the benefits of making their data more accessible and actionable, RAG could see broader implementation across various industries, from healthcare to customer service and beyond.
Innovative solutions to existing challenges. Ongoing research and development are likely to yield innovative solutions to current limitations, such as the hallucination issue, thereby enhancing the reliability and trustworthiness of AI assistants.
In conclusion, while RAG presents a promising frontier in AI technology, it’s not without its challenges. The road ahead will require persistent innovation, tailored strategies, and an open-minded approach to fully realize the potential of RAG in making AI interactions more accurate, relevant, and useful.





















{kind=link}